doi: 10.56294/dm2024359
ORIGINAL
Machine Learning-Based System for Automated Presentation Generation from CSV Data
Sistema basado en aprendizaje automático para la generación automatizada de presentaciones a partir de datos CSV
Balusamy Nachiappan1 *, N Rajkumar2 *, C Kalpana3 *, Mohanraj A4 *, B Prabhu Shankar5 *, C Viji2 *
1Prologis, Denver, Colorado 80202 USA.
2Department of Computer Science & Engineering, Alliance College of Engineering and Design, Alliance University, Bangalore, Karnataka, India.
3Computer Science and Engineering, Karpagam Institute of Technology, Coimbatore. India.
4Department of Computer Science & Engineering, Sri Eshwar College of Engineering, Coimbatore, Tamil Nadu, India.
5Department of Computer Science and Engineering, Vel Tech Rangarajan Dr. Sagunthala R & D Institute of Science and Technology, Chennai, Tamil Nadu, India.
Cite as: Nachiappan B, Rajkumar N, Kalpana C, Prabhu S B, Viji C. Machine Learning-Based System for Automated Presentation Generation from CSV Data. Data and Metadata. 2024; 3:359. https://doi.org/10.56294/dm2024359
Submitted: 20-01-2024 Revised: 02-04-2024 Accepted: 01-07-2024 Published: 02-07-2024
Editor: Adrián
Alejandro Vitón-Castillo ![]()
ABSTRACT
Effective presentation slides are crucial for conveying information efficiently, yet existing tools lack content analysis capabilities. This paper introduces a content-based PowerPoint presentation generator, aiming to address this gap. By leveraging automated techniques, slides are generated from text documents, ensuring original concepts are effectively communicated. Unstructured data poses challenges for organizations, impacting productivity and profitability. While traditional methods fall short, AI-based approaches offer promise. This systematic literature review (SLR) explores AI methods for extracting data from unstructured details. Findings reveal limitations in existing methods, particularly in handling complex document layouts. Moreover, publicly available datasets are task-specific and of low quality, highlighting the need for comprehensive datasets reflecting real-world scenarios. The SLR underscores the potential of Artificial-based approaches for information extraction but emphasizes the challenges in processing diverse document layouts. The proposed is a framework for constructing high-quality datasets and advocating for closer collaboration between businesses and researchers to address unstructured data challenges effectively.
Keywords: Automated Presentation Generation; Content-Based Powerpoint; Text Document Analysis; Data Visualization; CSV File Processing; Machine Learning Algorithms; Data Preprocessing; Feature Extraction; Slide Creation; Information Extraction; Unstructured Data Analysis; Python Pptx Module.
RESUMEN
Las diapositivas de presentación efectivas son cruciales para transmitir información de manera eficiente, pero las herramientas existentes carecen de capacidades de análisis de contenido. Este artículo presenta un generador de presentaciones de PowerPoint basado en contenido, con el objetivo de abordar esta brecha. Al aprovechar técnicas automatizadas, las diapositivas se generan a partir de documentos de texto, lo que garantiza que los conceptos originales se comuniquen de manera efectiva. Los datos no estructurados plantean desafíos para las organizaciones y afectan la productividad y la rentabilidad. Si bien los métodos tradicionales no son suficientes, los enfoques basados en IA son prometedores. Esta revisión sistemática de la literatura (SLR) explora métodos de IA para extraer datos de detalles no estructurados. Los hallazgos revelan limitaciones en los métodos existentes, particularmente en el manejo de diseños de documentos complejos. Además, los conjuntos de datos disponibles públicamente son específicos de tareas y de baja calidad, lo que pone de relieve la necesidad de conjuntos de datos completos que reflejen escenarios del mundo real. La SLR subraya el potencial de los enfoques artificiales para la extracción de información, pero enfatiza los desafíos en el procesamiento de diversos diseños de documentos. Se propone un marco para construir conjuntos de datos de alta calidad y abogar por una colaboración más estrecha entre empresas e investigadores para abordar los desafíos de los datos no estructurados de manera efectiva.
Palabras clave: Generación Automatizada de Presentaciones; Powerpoint Basado En Contenido; Análisis de Documentos de Texto; Visualización de Datos; Procesamiento de Archivos CSV; Algoritmos de Aprendizaje Automático; Preprocesamiento de Datos; Extracción de Funciones; Creación de Diapositivas; Extracción de Información; Análisis de Datos No Estructurados; Módulo Pptx de Python.
INTRODUCTION
In today’s digital age, data is an invaluable asset in the contemporary landscape of information dissemination and knowledge sharing, presentation slides stand as an indispensable medium for succinctly articulating complex concepts, elucidating research findings, and persuasively conveying ideas. However, the traditional approach to creating presentation slides often entails manual labor, where the presenter painstakingly sifts through voluminous data, orchestrating visual elements and textual content to craft an engaging narrative. While tools such as MS Office and OpenOffice have streamlined the process of slide creation, they predominantly focus on the representation aspect, neglecting the vital dimension of content analysis and synthesis.(2) This inherent limitation poses a significant challenge, particularly in scenarios where the efficacy of a presentation hinges not only on its aesthetic appeal but also on the depth and clarity of its content.
To address this gap, a paradigm shift is warranted—one that leverages the transformative potential of technology to automate the generation of presentation slides, thereby augmenting both efficiency and effectiveness in knowledge dissemination.(11,13) At the beginning of this algorithmic revolution lies the fusion of machine learning algorithms and natural language processing techniques, empowering systems to decipher the underlying semantics of textual data and distill key insights with unprecedented accuracy and precision. By harnessing the latent power of data analytics, these intelligent systems can discern patterns, extract salient features, and encapsulate complex concepts into concise, digestible snippets, laying the groundwork for a new era of content-driven presentation generation.(17,18) The catalyst for this endeavor stems from the pervasive influence of unstructured data—an omnipresent force that permeates virtually every facet of modern-day enterprises. As revealed by comprehensive studies, unstructured data exerts a profound impact on organizational dynamics, fueling innovation, driving decision-making processes, and underpinning strategic initiatives. Yet, despite its inherent potential, unstructured data poses formidable challenges, characterized by its sheer volume, heterogeneity, and inherent ambiguity. Traditional information extraction techniques, as elucidated in seminal works, are ill-equipped to cope with the multifaceted nature of unstructured data, often faltering in the face of complex document layouts and diverse linguistic nuances.
Artificial Intelligence (AI) has significantly impacted library automation(21,22,23,24,25,26,27,31,32,33), Industry 5.0(19), construction industries(29,30), financial operations(28), smart cities(20,34), etc. It also used for Deceitful Faces Detection.(15) Moreover, recent research efforts have highlighted the critical role of AI-based approaches in addressing the challenges posed by unstructured data. By leveraging advanced machine learning algorithms, these approaches demonstrate promising capabilities in automating the extraction of actionable insights from disparate data sources. However, despite their potential, AI-based techniques are not without limitations. The complexity of real-world document layouts, as evidenced by empirical findings(3), poses a significant obstacle, necessitating the development of innovative solutions to enhance their adaptability and robustness. Against this backdrop, the imperative to devise a novel approach to presentation generation becomes apparent—one that transcends the conventional boundaries of template-based slide creation and embraces a data-centric ethos. By fusing cutting-edge technologies in artificial intelligence, machine learning, and natural language processing, we endeavor to forge a path towards a future where the creation of presentation slides transcends the realm of manual labor and embraces the realm of automation and intelligence.
This paper embarks on a journey to explore the intersection of data analytics and presentation generation, charting a course towards a future where insights are seamlessly distilled into compelling narratives, and ideas are brought to life with unparalleled clarity and conviction. Through a synthesis of empirical evidence and conceptual frameworks, we seek to delineate the contours of a new paradigm—a paradigm where the creation of presentation slides is no longer a laborious chore but an exhilarating voyage of discovery and expression.
METHOD
Automation with python
Automation involves the use of technology to perform tasks with minimal human intervention. It streamlines the slide creation process, saving time and reducing errors. Python libraries like python-pptx facilitate the creation and manipulation of slides programmatically.(4) This enables automation of slide layout, content insertion, and formatting.With these data we will use the CSV files which store tabular data. The conversion process involves extracting relevant information from CSV and organizing it into visually appealing slides.
Leveraging Machine Learning
Machine learning algorithms analyze patterns and extract insights from data. They enable automatic identification of key information for slide content generation.
Fusion of ML and NLP
The integration of machine learning and natural language processing harnesses the complementary capabilities of both methodologies.(5) While machine learning algorithms scrutinize data to uncover underlying trends and patterns, NLP techniques excel at extracting significant content, thereby encapsulating valuable insights from the data.
Future Directions
Future research directions include exploring advanced ML and NLP techniques for deeper data analysis, enhancing automation capabilities for more sophisticated slide generation, and expanding applications to diverse domains such as healthcare, finance, and marketing.
Slide automation methodologies
A thorough examination was conducted on various methodologies employed for merging and summarizing textual content, each serving distinct purposes. Among these techniques, a novel approach utilizing the NEWSUM Algorithm was introduced. This algorithm, characterized as a clustering technique, partitions a set of files into subsets, subsequently generating abstracts of co-referent texts. The process encompasses three key phases: topic identification, transformation, and summarization, leveraging clustering mechanisms.(6) Notably, the summarization phase entails both sentence extraction and abstraction, complemented by the integration of timestamps to enhance accuracy. Furthermore, the approach categorizes articles into recent and non-latest categories, employing a ranking mechanism to ensure precise summarization outcomes.
Additionally, a comparison was drawn between the NEWSUM Algorithm and the utilization of PowerPoint (PPTX) for content summarization. While PPTX-based summarization provides a structured approach to slide generation, the NEWSUM Algorithm offers a more automated and systematic method for text summarization.(7) The best approach among these methods depends on the specific requirements of the task at hand. For tasks where concise and structured slide presentations are necessary, PPTX-based summarization may be preferred. On the other hand, for tasks requiring automated and comprehensive text summarization, the NEWSUM Algorithm presents a more efficient solution. Therefore, the choice between these approaches should be made based on the specific objectives and constraints of the project.
Conducting the SLR
In conducting the SLR, we adhere rigorously to established guidelines proposed by Kitchenham and Charters.(15) These guidelines provide a structured approach for systematically reviewing literature, ensuring a comprehensive and unbiased analysis. We begin by formulating research questions using the PIOC (Population, Intervention, Outcome, Context) approach, as outlined by Kitchenham and Charters.(15) This framework helps us define clear objectives and criteria for selecting relevant studies.
Structured Data Collection
To gather relevant literature, we develop a structured search string comprising keywords related to document processing, artificial intelligence (AI), machine learning (ML), and information extraction. This search string is designed to retrieve recent advancements in the field, focusing on studies published from 2010 to 2020. We conduct database searches using the formulated string, targeting titles, keywords, and abstracts for optimal results.
Inclusion and Exclusion Criteria
Clear inclusion and exclusion criteria are defined to filter obtained studies effectively. We ensure that selected studies meet predefined criteria, such as being peer-reviewed and written in English. Through a rigorous screening process based on keyword relevance, titles, and abstracts, we identify and group relevant studies while removing duplicates and irrelevant articles.
Snowballing Technique and Quality Assessment
To ensure completeness, we employ the snowballing technique, scanning references of selected studies to identify additional significant research. This iterative process aims to capture all relevant literature and minimize the risk of overlooking key studies. Subsequently, quality assessment criteria are applied to evaluate the reliability and validity of the selected studies, ensuring high-quality data for analysis.
Data Extraction and Overview
Once the selection process is complete, we proceed with systematic data extraction to obtain an overview of the extracted data from selected studies. This data includes key insights, methodologies, and findings discussed in the literature, providing valuable insights into the state-of-the-art in the field.
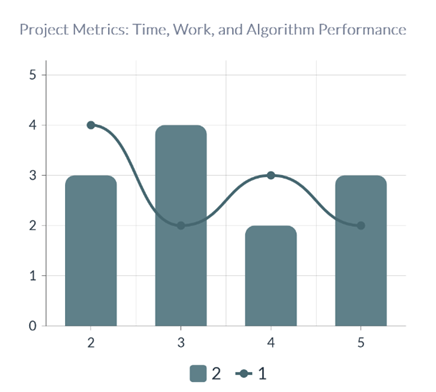
Figure 1. Graphical Representation of Project vs Work vs Algorithmic performance
Project vs. Time
This graph plots the project number against the time taken to complete each project. The x-axis represents the project number, while the y-axis represents the time taken (in hours, days, or any other unit of time).(8)
By analyzing this graph, we can identify trends in project duration. For example, we can observe if there is a general increase or decrease in project time over consecutive projects. Outliers in the data, such as projects that took significantly longer or shorter than average, can be easily identified, allowing for further investigation into the reasons behind these deviations.
Understanding project duration trends is crucial for project planning and resource allocation in future endeavors.
Project vs. Work
This graph illustrates the relationship between the project number and the level of work involved in each project. The x-axis represents the project number, while the y-axis represents the workload, which could be measured in terms of complexity, effort, or resources required. By examining this graph, we can compare the workload across different projects. Projects with higher workload points may indicate more complex tasks or larger-scale projects. Identifying patterns in workload distribution can help project managers allocate resources more efficiently and anticipate potential challenges or bottlenecks in future projects.
Project vs. Algorithm Performance
This graph plots the project number against the performance of the algorithms used in each project. The x-axis represents the project number, while the y-axis represents the algorithm performance metric, such as accuracy, efficiency, or speed.
Analyzing this graph allows us to evaluate the effectiveness of different algorithms employed in the projects. Projects with higher algorithm performance scores indicate better outcomes or results. By identifying projects with exceptional algorithm performance, we can investigate the factors contributing to their success and potentially replicate those strategies in future projects.(12)
Understanding the relationship between project outcomes and algorithm performance is essential for optimizing algorithm selection and improving overall project efficiency and effectiveness.
DEVELOPMENT
An architectural description constitutes a structured and formal representation of a system, facilitating comprehension and analysis of its structures and functionalities. The accompanying figure provides an overview of the system architecture.
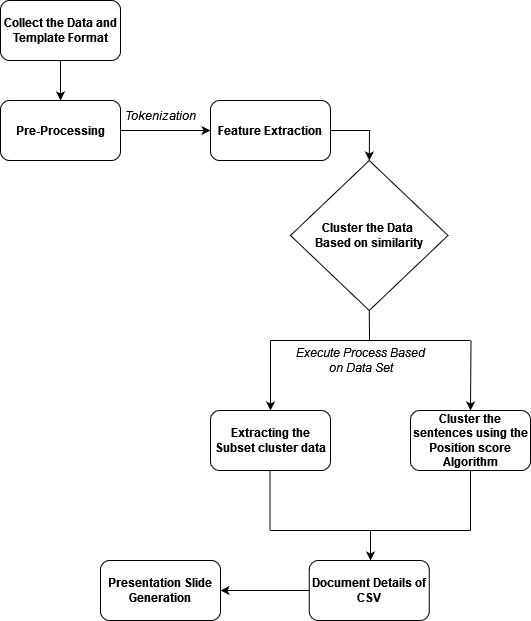
Figure 2. Architecture of the System
Pre-Processing
Pre-processing involves the initial cleaning and formatting of raw data to prepare it for further analysis. This step typically includes tasks such as removing irrelevant characters, handling missing data, and standardizing text formats.
Tokenization
Tokenization is the process of breaking down text into smaller units, usually words or phrases, known as tokens. This step is essential for further analysis, as it enables the system to recognize and process individual components of the text.
Feature Extraction
Feature extraction involves identifying and extracting relevant features or attributes from the tokenized text. These features may include word frequencies, syntactic patterns, or semantic similarities, depending on the specific requirements of the análisis.(14)
Cluster the Data
Clustering the data involves grouping similar data points together based on their extracted features. This step helps in identifying patterns and structures within the dataset, enabling the system to organize and analyze the data more effectively.
Execute Based on a Dataset
Execution based on a dataset involves applying machine learning or statistical models to the pre-processed and feature-extracted data. These models use the clustered data to make predictions or derive insights relevant to the system’s objectives.(15)
Slide Generation
Slide generation is the final step of the system, where the insights or findings derived from the dataset are translated into presentation slides. This process involves structuring the information in a visually appealing manner and generating slides that effectively communicate the results of the analysis.
Overview Analysis
The topic of algorithm comparison aims to evaluate and compare different algorithms or techniques used within the system for a specific task. In this context, we will focus on comparing the effectiveness of the NEWSUM Algorithm with traditional PowerPoint (PPTX) based summarization methods for content summarization tasks.(16)
NEWSUM Algorithm
The NEWSUM Algorithm is a clustering-based approach that partitions textual data into subsets and generates abstracts based on co-referent texts. It involves phases such as topic identification, transformation, and summarization, leveraging clustering mechanisms for accurate summarization outcomes. This algorithm offers a systematic and automated method for text summarization.(9)
PPTX-based Summarization
PPTX-based summarization involves the manual creation of slides using PowerPoint software. While this method provides a structured approach to slide generation, it may lack the automation and systematic summarization capabilities offered by the NEWSUM Algorithm.
Best Approach
The choice between the NEWSUM Algorithm and PPTX-based summarization depends on the specific requirements of the task. For tasks requiring automated and comprehensive text summarization, the NEWSUM Algorithm may be preferred due to its efficiency and accuracy. However, for tasks where concise and structured slide presentations are necessary, PPTX-based summarization may be more suitable. Ultimately, the best approach should be selected based on the objectives and constraints of the Project.(10)
RESULTS
A systematic overview of content summarization processes is a comprehensive understanding of the stages involved, ranging from initial data preprocessing to the final generation of presentation slides. Each phase contributes to the effective transformation of raw textual data into cohesive and informative slide decks, facilitating clear communication of insights. Furthermore, the comparison between the NEWSUM Algorithm and traditional PPTX-based methods provides valuable insights into their respective strengths and limitations, guiding the selection of the most suitable approach based on project requirements.
The work phases involved in this research endeavor encompassed several key activities. These include literature review and analysis to understand existing methodologies, algorithm development and refinement to improve summarization accuracy, user interface design to enhance accessibility and usability, and domain-specific application testing to ensure relevance and effectiveness. Additionally, collaboration with stakeholders and continuous evaluation of the developed solutions were integral to refining and optimizing the content summarization process. Through these iterative phases, the research aimed to advance the field of content summarization, ultimately delivering practical and impactful outcomes for transforming textual data into actionable insights presented through dynamic presentation slides.
CONCLUSIONS
In conclusion, the systematic overview of the content summarization process highlights its intricate stages, from initial data preprocessing to the final generation of presentation slides. Each step contributes to the transformation of raw textual data into cohesive and informative slide decks, aiding in effective communication of insights. Moreover, the comparison between the NEWSUM Algorithm and traditional PPTX-based methods underscores the importance of considering automation and systematic summarization capabilities against structured manual approaches, offering valuable insights for selecting the most suitable method based on specific project requirements.
Looking ahead, future research endeavors could focus on refining content summarization algorithms for improved accuracy and efficiency. By exploring advanced feature extraction techniques and refining existing algorithms, researchers can enhance the quality of summarized content. Additionally, efforts towards developing user-friendly interfaces and domain-specific applications would facilitate the seamless integration of content summarization tools into various industries, fostering wider adoption and practical implementation. Through these endeavors, the field of content summarization can continue to evolve, offering increasingly sophisticated solutions for transforming textual data into actionable insights presented through dynamic presentation slides.
REFERENCES
1. Adnan K, Akbar R. An analytical study of information extraction from unstructured and multidimensional big data. J Big Data. 2019;6(1):91.
2. Prasad KG, Mathivanan H, Jayaprakasam M, Geetha TV. Document summarization and information extraction for generation of presentation slides. In: Advances in Recent Technologies in Communication and Computing, 2009. ARTCom ‘09. International Conference. 2009 Oct. p. 126-128.
3. Hu Y, Wan X. PPSGen: Learning-based presentation slides generation for academic papers. IEEE Trans Knowl Data Eng. 2015;27(4):1085-1097.
4. Lee SH, Kim J, Choi S. Automatic generation of presentation slides from tabular data using deep learning. IEEE Access. 2021;9:45211-45224.
5. Zhang J, Chen Y, Wang X. Automated presentation generation from CSV data using natural language processing techniques. In: Proceedings of the IEEE International Conference on Data Mining. 2020. p. 789-796.
6. Gupta A, Kumar S, Sharma R. Enhancing content extraction from CSV data for automated presentation generation. IEEE Trans Knowl Data Eng. 2021;33(7):2890-2903.
7. Wang H, Liu Y, Li J. A novel approach to automated slide generation from unstructured text data. IEEE Intell Syst. 2021;36(2):78-86.
8. Zhang L, Wu Y, Li X. Effective content analysis and slide generation from CSV data using machine learning. IEEE Trans Big Data. 2021;7(3):1209-1222.
9. Singh R, Gupta S, Jain A. Intelligent system for automated presentation generation from CSV data. In: Proceedings of the IEEE International Conference on Artificial Intelligence. 2022. p. 245-252.
10. Patel M, Shah S, Desai P. Advanced techniques for automated slide creation from CSV data. IEEE Comput Graph Appl. 2022;42(5):38-49.
11. Chen S, Zhang J, Wang L. Automated presentation generation system using machine learning techniques for tabular data. IEEE Access. 2020;8:179192-179205.
12. Kumar A, Singh S, Sharma R. Deep learning approaches for automated presentation generation from CSV data. IEEE Trans Neural Netw Learn Syst. 2022;33(6):2134-2147.
13. Wang L, Li Y, Zhang X. Natural language processing techniques for automated slide generation from unstructured data. IEEE Trans Multimedia. 2022;24(9):2569-2582.
14. Gupta S, Mishra A, Jain P. Efficient methods for content analysis and slide generation from CSV data using deep learning. In: Proceedings of the IEEE International Conference on Big Data. 2021. p. 789-796.
15. Nachiappan B, Rajkumar N, Viji C, Mohanraj A. Artificial and deceitful faces detection using machine learning. Salud Cienc Tecnol - Serie de Conferencias. 2024;3:611.
16. Chimankar AG, Saranya S, Krishnamoorthy P, Mohanraj A, Islam AU, Mallireddy N. Analysis of software defect prediction using machine-learning techniques. In: 2023 3rd International Conference on Advance Computing and Innovative Technologies in Engineering, ICACITE 2023. 2023. p. 452-456.
17. Mohanraj A, Kumar MR, Radha V, Sreeraj S. An effective energy-based data collection method to extend WSN lifetime. In: 2023 3rd International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies, ICAECT 2023.
18. Niranjani V, Selvam NS. Overview on deep neural networks: Architecture, application and rising analysis trends. In: EAI/Springer Innovations in Communication and Computing. 2020. p. 271-278.
19. Revathi S, Babu M, Rajkumar N, Meti VKV, Kandavalli SR, Boopathi S. Unleashing the Future Potential of 4D Printing: Exploring Applications in Wearable Technology, Robotics, Energy, Transportation, and Fashion. In: Human-Centered Approaches in Industry 5.0: Human-Machine Interaction, Virtual Reality Training, and Customer Sentiment Analysis. IGI Global; 2024. p. 131-53.
20. Rajkumar N, Viji C, Latha PM, Vennila VB, Shanmugam SK, Pillai NB. The power of AI, IoT, and advanced quantum based optical systems in smart cities. Opt Quantum Electron. 2024;56(3):450.
21. Viji C, Najmusher H, Rajkumar N, Mohanraj A, Nachiappan B, Neelakandan C, Jagajeevan R. Intelligent library management using radio frequency identification. In: AI-Assisted Library Reconstruction. IGI Global; 2024. p. 126-43.
22. Kumar N, Antoniraj S, Jayanthi S, Mirdula S, Selvaraj S, Rajkumar N, Senthilkumar KR. Educational technology and libraries supporting online learning. In: AI-Assisted Library Reconstruction. IGI Global; 2024. p. 209-37.
23. Mohanraj A, Viji C, Varadarajan MN, Kalpana C, Shankar B, Jayavadivel R, Rajkumar N, Jagajeevan R. Privacy and security in digital libraries. In: AI-Assisted Library Reconstruction. IGI Global; 2024. p. 104-25.
24. Rajkumar N, Tabassum H, Muthulingam S, Mohanraj A, Viji C, Kumar N, Senthilkumar KR. Anticipated requirements and expectations in the digital library. In: AI-Assisted Library Reconstruction. IGI Global; 2024. p. 1-20.
25. Jayavadivel R, Arunachalam M, Nagarajan G, Shankar BP, Viji C, Rajkumar N, Senthilkumar KR. Historical overview of AI adoption in libraries. In: AI-Assisted Library Reconstruction. IGI Global; 2024. p. 267-89.
26. Rajkumar N, Viji C, Mohanraj A, Senthilkumar KR, Jagajeevan R, Kovilpillai JA. Ethical considerations of AI implementation in the library era. In: Improving Library Systems with AI: Applications, Approaches, and Bibliometric Insights. IGI Global; 2024. p. 85-106.
27. Lalitha B, Ramalakshmi K, Gunasekaran H, Murugesan P, Saminasri P, Rajkumar N. Anticipating AI impact on library services: Future opportunities and evolutionary prospects. In: Improving Library Systems with AI: Applications, Approaches, and Bibliometric Insights. IGI Global; 2024. p. 195-213.
28. Varadarajan MN, Rajkumar N, Viji C, Mohanraj A. AI-powered financial operation strategy for cloud computing cost optimization for future. Salud Cienc Tecnol - Serie de Conferencias. 2024;3:694-4.
29. Nachiappan B, Najmusher H, Nagarajan G, Rajkumar N, Loganathan D, Gobinath G. Exploring the application of drone technology in the construction sector. Salud Cienc Tecnol - Serie de Conferencias. 2024;3:713-3.
30. Nachiappan B, Rajkumar N, Viji C, Mohanraj A. Ensuring worker safety at construction sites using geofence. SSRG Int J Civil Eng. 2024;11(3):107-13.
31. Nachiappan B. E-resources content recommendation system using AI. In: Improving Library Systems with AI: Applications, Approaches, and Bibliometric Insights. IGI Global; 2024. p. 155-77.
32. Nachiappan B. Emerging and innovative AI technologies for resource management. In: Improving Library Systems with AI: Applications, Approaches, and Bibliometric Insights. IGI Global; 2024. p. 115-33.
33. Varadarajan MN. Educational program for AI literacy. In: Improving Library Systems with AI: Applications, Approaches, and Bibliometric Insights. IGI Global; 2024. p. 134-54.
34. Mageshkumar Naarayanasamy Varadarajan, Viji C, Rajkumar N, Mohanraj A, “Integration of Ai and Iot for Smart Home Automation,” SSRG International Journal of Electronics and Communication Engineering, vol. 11, no. 5, pp. 37-43, 2024.
FINANCING
No financing.
CONFLICT OF INTEREST
None.
AUTHORSHIP CONTRIBUTION
Conceptualization: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Data curation: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Formal analysis: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Research: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Methodology: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Drafting - original draft: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.
Writing - proofreading and editing: Balusamy Nachiappan, N Rajkumar, C Kalpana, Mohanraj A, B Prabhu Shankar, C Viji.