doi: 10.56294/dm2024276
ORIGINAL
GAN-based E-D Network to Dehaze Satellite Images
Red E-D basada en GAN para retocar imágenes de satélite
Sudhamalla Mallesh1
![]() *, D. Haripriya1
*, D. Haripriya1 ![]() *
*
1Department of ECE, Anurag University. Ghatkesar, Hyderabad, Telangana State-500 088, India.
Cite as: Sudhamalla M, D H. GAN-based E-D Network to Dehaze Satellite Images. Data and Metadata. 2024; 3:276. https://doi.org/10.56294/dm2024276
Submitted: 02-10-2023 Revised: 12-02-2024 Accepted: 27-05-2024 Published: 28-05-2024
Editor: Adrián
Alejandro Vitón Castillo ![]()
ABSTRACT
The intricate nature of remote sensing image dehazing poses a formidable challenge due to its multifaceted characteristics. Considered as a preliminary step for advanced remote sensing image tasks, haze removal becomes crucial. A novel approach is introduced with the objective of dehazing an image employing an encoder-decoder architecture embedded in a generative adversarial network (GAN). This innovative model systematically captures low-frequency information in the initial phase and subsequently assimilates high-frequency details from the remote sensing image. Incorporating a skip connection within the network serves the purpose of preventing information loss. To enhance the learning capability and assimilate more valuable insights, an additional component, the multi-scale attention module, is introduced. Drawing inspiration from multi-scale networks, an enhanced module is meticulously designed and incorporated at the network’s conclusion. This augmentation methodology aims to further enhance the dehazing capabilities by assimilating context information across various scales. The material for fine-tuning the dehazing algorithm has been obtained from the RICE-I dataset that serves as the testing ground for a comprehensive comparison between our proposed method and other two alternative approaches. The experimental results distinctly showcase the superior efficacy of our method, both in qualitative and quantitative terms. Our proposed methodology performed better with respect to contemporary dehazing techniques in terms of PSNR and SSIM although it requires longer simulation times. So, it could be concluded that we contributed a more comprehensive RS picture dehazing methodology to the existing dehazing methodology literature.
Keywords: Dehazing; Generative Adversarial Network; Generator; Discriminator.
RESUMEN
La intrincada naturaleza de la desdibujación de imágenes de teledetección plantea un reto formidable debido a sus multifacéticas características. La eliminación de la niebla se considera un paso preliminar para las tareas avanzadas de teledetección de imágenes. Se introduce un nuevo enfoque con el objetivo de desdibujar una imagen empleando una arquitectura codificador-decodificador integrada en una red generativa adversarial (GAN). Este innovador modelo captura sistemáticamente la información de baja frecuencia en la fase inicial y posteriormente asimila los detalles de alta frecuencia de la imagen de teledetección. La incorporación de una conexión de salto dentro de la red sirve para evitar la pérdida de información. Para mejorar la capacidad de aprendizaje y asimilar más información valiosa, se introduce un componente adicional, el módulo de atención multiescala. Inspirándose en las redes multiescala, se diseña meticulosamente un módulo mejorado que se incorpora a la conclusión de la red. Esta metodología de aumento pretende mejorar aún más las capacidades de desdibujamiento asimilando información contextual a varias escalas. El material para perfeccionar el algoritmo de desdibujamiento se ha obtenido del conjunto de datos RICE-I, que sirve de campo de pruebas para una comparación exhaustiva entre nuestro método propuesto y otros dos enfoques alternativos. Los resultados experimentales muestran claramente la eficacia superior de nuestro método, tanto en términos cualitativos como cuantitativos. Nuestra metodología propuesta obtuvo mejores resultados en términos de PSNR y SSIM que las técnicas de dehazing actuales, aunque requiere tiempos de simulación más largos. Por lo tanto, se puede concluir que hemos contribuido con una metodología de dehazing de imágenes RS más completa a la literatura existente sobre metodologías de dehazing.
Palabras clave: Dehazing; Red Adversarial Generativa; Generador; Discriminador.
INTRODUCTION
Satellite imagery plays a pivotal role in acquiring comprehensive information about Earth's surface, yet its utility is hindered by atmospheric phenomena such as haze. The challenge of haziness in remote sensing images has prompted diverse methodologies to enhance clarity and improve interpretation accuracy. This introductory synthesis on the basis of the articles,(1,2,3,4,5,6,7,8,9,10) encapsulates the essence of several cutting-edge dehazing approaches. A categorization of current algorithms into image enhancement, physical dehazing, and data-driven paradigms sets the stage for a nuanced exploration of their advantages and disadvantages. Notably, a novel unsupervised approach introduces the Edge-Sharpening Cycle-Consistent Adversarial Network (ES-CCGAN), leveraging cycle generative adversarial networks to eliminate haze from high-resolution optical remote-sensing images without the need for prior information.
Hence, a dehazing methodology based on generative adversarial networks is proposed, directly yielding dehazed images without the need for intermediate parameter estimation. The architecture of the generative adversarial network for dehazing comprises two components: the generative network and the discriminative network. The generative network is tasked with producing the dehazed image, while the discriminative network determines whether the input is a haze-free or dehazed image. During the training phase, it initially employs the hazy image as the input for the generative network to generate a dehazed image. Subsequently, it utilizes both the dehazed image and a haze-free image as inputs for the discriminative network. The parameters of both networks are adjusted based on the discriminative network's output. Through repeated training, the discriminative network becomes incapable of distinguishing between haze-free and dehazed images. Upon completion of training, the generative network is employed for actual image dehazing.
The generative network in our design adopts an encoder-decoder structure to comprehend the transformation from a hazy image to a dehazed image. Through a down-sampling technique that progressively diminishes the feature map's size, we can eliminate haze and concurrently extract features from various image levels. During the decoding phase, an up-sampling approach is employed to rebuild the image, restoring its finer features. To prevent information loss in the deep network, we introduce skip connections within the generative network. Additionally, an attention mechanism is incorporated into the network through the design of the Attention module, enhancing the network's focus on crucial features. To capture diverse receptive fields beneficial for learning both rough and fine image information, we introduce the CBlock module composed of 3 convolution layers. This module ensures simultaneous learning of various image features, mitigating information loss. Moreover, a distillation module is devised to replace a convolution layer in the network, reducing overall parameters. Finally, an enhance module is positioned at the network's end, amalgamating multi-scale features to acquire more comprehensive context information.
Related Literature
In recent times, a substantial array of dehazing methodologies has surfaced, predominantly categorized different classes presented by Liu et al.(1) where a primary undertaking involves the categorization of presently accessible algorithms into three distinct classes: image enhancement, physical dehazing, and data-driven methodologies. Hu et al.(2) introduces an innovative unsupervised approach designed for the elimination of haze from high-resolution optical remote-sensing imagery. The methodology proposed herein, labeled as the edge-sharpening cycle-consistent adversarial network (ES-CCGAN), leverages cycle generative adversarial networks as its foundational framework. Gu et al.(3) introduces a pioneering approach dubbed the prior-based dense attentive dehazing network (DADN) emerges as the proposed solution for the singular task of removing haze from individual remote sensing images. Huang et al.(4) leads to the establishment of a dataset named SateHaze1k unfolds, comprising a collection of 1200 image pairs encompassing clear Synthetic Aperture Radar (SAR), hazy RGB, and their corresponding ground truth images. This dataset meticulously categorizes images into three distinct degrees of haze: thin, moderate, and thick fog, providing a structured and diverse set for research and evaluation purposes. In Jiang et al.(5) the issue of clarity in remote sensing images afflicted by non-uniform haze, a preliminary processing step is introduced. This step involves subjecting the input image to a dehazing technique rooted in the atmospheric scattering model. Gui et al.(6) undertakes a comprehensive examination of supervised, semi-supervised, and unsupervised methodologies employed for the dehazing of individual images. Ni et al.(7), introduced for the elimination of haze in individual satellite images. This methodology is meticulously formulated through the amalgamation of the linear intensity transformation (LIT) technique and local property analysis (LPA). Shengdong Zhang et al.(8), introduced generative adversarial and self-supervision method for boosting the performance on hazy images, this model mainly address domain shift problem to improve the appearance of the image. Jin et al.(9) introduced LFD-Net employs ASM for approximating the atmospheric light and transmission map to increasing the restoration capability. A dual multi-scale dehazing network is proposed by Zhang et al.(10), which consists coarse multi-scale network and fine multi scale blocks and it is used three scales of information to extract global and local features of the images for better dehazing. Notably, the DCP method, introduced by He et al.(11), employs the dark channel prior to haze removal in a single image, identifying pixels with low intensity in the clear image's color channel. Color Attenuation Prior method proposed by Zhu et al.(12). This method utilizes linear color attenuation prior to establish a linear model, relying on the disparity between pixel brightness and saturation within the hazy image. Akshay et al.(13) introduced LIGHT-Net which represents a novel advancement in image de-hazing. This network comprises two integral components: the color constancy module and the haze reduction module. The primary function of the color constancy module lies in the mitigation of color cast introduced by adverse weather conditions in hazy images. Simultaneously, the haze reduction module, a pivotal element of LIGHT-Net, employs an inception-residual block structure to systematically diminish the impact of haze while promoting heightened visibility within the hazy image. Li et al.(14) introduced a two-stage dehazing neural network, designated as FCTF-Net, employing a sequential "first-coarse-then-fine" approach. Characterized by its simplicity and effectiveness, this network structure orchestrates a tandem process: the initial stage of image dehazing harnesses an encoder–decoder architecture to extract multiscale features. Consequently, this extraction lays the foundation for the subsequent second stage of dehazing, enhancing the refinement of outcomes attained in the preceding stage. Chen et al.(15) proposed hybrid high-resolution learning network framework, H2RL-Net. This framework distinguishes itself through a sophisticated feature extraction architecture, ensuring meticulous spatial precision through the primary high-resolution branch. Concurrently, a supplementary ensemble of multiresolution convolution streams is employed to amass features of heightened semantic richness, thus enhancing the network's overall capability. Li et al.(16) pursue an end-to-end photo-realistic dehazing technique development through the orchestrated interplay of a pair of neural networks engaged in an adversarial game. To circumvent the pitfall of uniform contrast enhancement, the generator's learning process is designed to concurrently accomplish the restoration of haze-free images while adeptly capturing the nuanced non-uniformity inherent in the distribution of haze.
Proposed Dehazing Technique
To enhance the dehazing efficacy for the remote sensing images, an advanced dehazing method based on generative adversarial network (GAN) is proposed. This method ensures superior dehazing outcomes and heightened clarity in image details. Comprising two essential components, the dehazing network consists of a generative network and a discriminative network. The generative network is constructed as an encoder-decoder featuring an attention module. It takes the hazy image as input and directly produces the dehazed image at the network's conclusion. Simultaneously, the discriminative network discerns whether the input image is the dehazed or haze-free version. The encoder-decoder network undergoes constraint by a loss function (given in equation 2) involving variables such as the encoder-decoder network's output, the haze-free image, and the discriminative network's output. Optimization of the loss function is achieved through the Adam optimizer, ensuring optimal dehazing performance. Ultimately, when the discriminator is unable to distinguish between the dehazed and haze-free images, then the network concludes its training.
The design of the generative network involves an encoder-decoder network tailored to eliminate haze from hazy images. The generative network comprises two distinct sections: the encoding segment and the decoding segment. In the encoding phase, continual reduction of the feature map's size enhances the network's receptive field, facilitating the assimilation of low-frequency information encompassing the overall image outline. In the decoding phase, feature map expansion directs the network's focus toward high-frequency information encompassing intricate image details. The integration of low-frequency and high-frequency information is accomplished through a short skip connection, ensuring the comprehensive learning of all image details. Additionally, a local skip connection is introduced in the generative network to prevent information loss. The structural representation of the generative network is illustrated in figure 1.
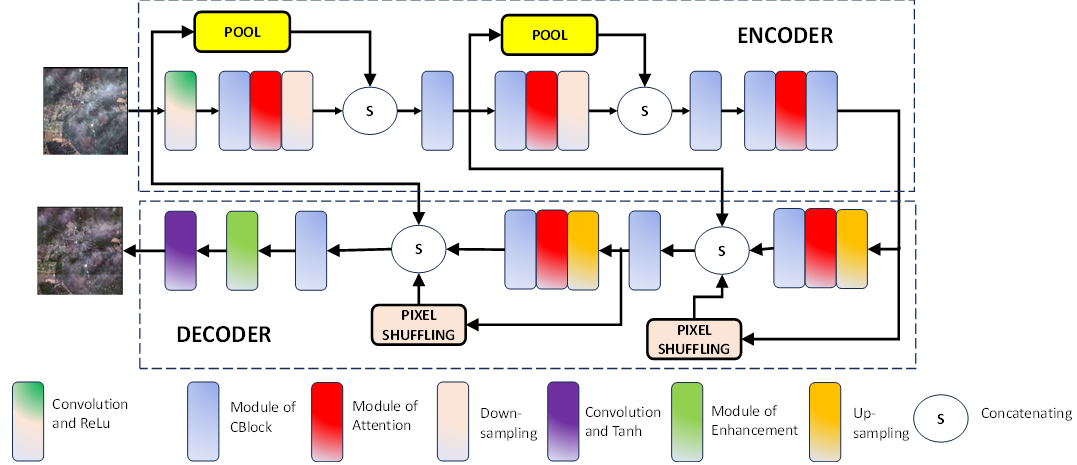
Figure 1. Generative Adversarial Network under proposition
Within the encoding phase, the initial step involves employing a convolution layer and the Rectified Linear Unit (ReLU) activation function to discern local features within the remote sensing image. This process concurrently elevates the channel count from 3 to 64. Following this, the application of the CBlock module and attention module ensues, sustaining the extraction of more potent features while maintaining an output channel count of 64. Subsequently, a down-sampling convolution operation is implemented to contract the feature map's size, achieving a reduction to half of the input feature map's dimensions. Concurrently, the channel count undergoes augmentation from 64 to 128.Simultaneously, the feature map generated by the initial convolution layer and ReLU activation undergoes down-sampling through pooling operations, resulting in a 64-channel output. The amalgamation of these two down-sampled feature maps transpires through concatenation operations, establishing a local skip connection that serves to preempt information loss. Proceeding further, a subsequent CBlock module integrates the spliced feature map, adjusting the channel count from 192 to 128. Analogously, a reduction in the feature map's size to one-quarter of its original dimensions occurs, accompanied by a channel count increment to 256 at the subsequent scale. This intricate process ensures an iterative refinement of features through multi-scale operations in the encoding pipeline. Subsequently, an attention module, along with two CBlock modules, is employed to extract more potent features, maintaining the original size of the feature map and the number of output channels. Within the decoding phase, the reconstruction of features takes place through an up-sampling convolution, an attention module, and a CBlock module. This process entails the restoration of the feature map's size to half of the original remote sensing image, while concurrently reducing the channel count from 256 to 128.Further in the decoding process, pixel shuffle is utilized for up-sampling the feature map, effectively diminishing the number of output channels from 256 to 64. The amalgamation of two up-sampled feature maps ensues through a concatenation operation, constituting a local skip connection that proves instrumental in preventing information loss arising from increased network depth. Within the devised network, as illustrated in figure 1, an intricate Attention module, depicted in figure 2, has been meticulously crafted. Diverging from the spatial attention module, a noteworthy augmentation involves the integration of a multi-scale module. This supplementary module encompasses a sequence of operations, comprising down-sampling, three convolution layers, and upsampling. It deviates from the conventional equal treatment of each pixel, instead, assigning distinct weights to pixels contingent upon the wealth of information encapsulated. The pixel weights, reflective of the information content, enable the network to accord varying degrees of attention to the learning process, facilitating a nuanced focus on crucial information. By virtue of the multi-scale operation, divergent receptive fields are engaged, affording an elevation in attention precision, contrasting favorably with the unidimensional focus of the single-scale attention module. Within figure 2, the attention module manifests through a tripartite configuration. The inaugural branch manifests as a shortcut connection meticulously engineered to perpetuate the unaltered information residing within the input feature map. Sequentially, the second branch materializes through an amalgamation of channel pooling, concatenation operation, convolution layer, and sigmoid activation function. The channel pooling operation undertakes the integration of channel-specific details within the input. Through concatenation, the outputs of the third branch and channel pooling are seamlessly fused. A convolution layer orchestrates the amalgamation of feature map information. To derive weight, crucial in the process, the sigmoid activation function is instrumental. The third branch, engineered for multi-scale feature extraction, encompasses a carefully orchestrated sequence involving down-sampling, three convolution layers, and up-sampling.
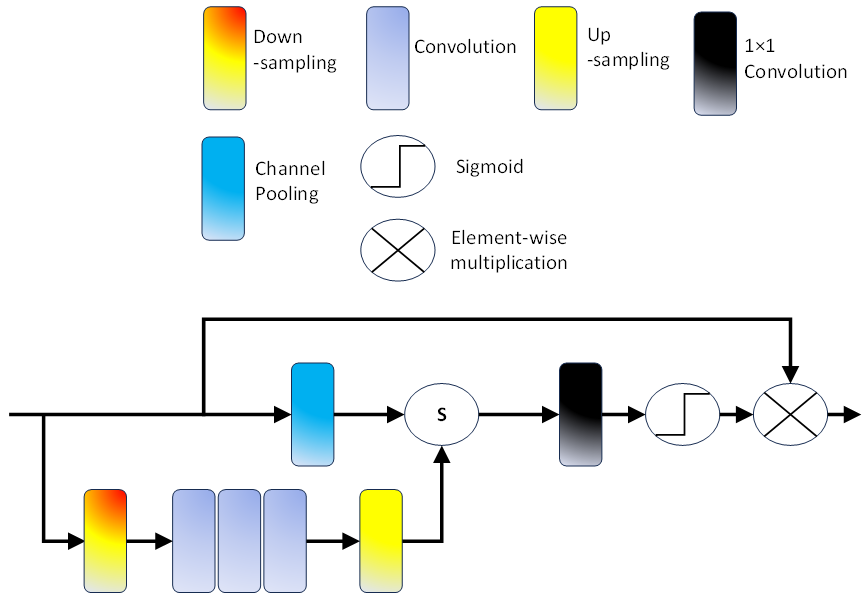
Figure 2. Module of Attention
The down-sampling operation contracts the feature map dimensions, paving the way for three convolution layers to extricate more refined feature insights. Subsequently, the up-sampling operation meticulously restores the feature map dimensions to match the original specifications. Culminating in the multiplication of the input feature map by the weight engendered by the second branch, the output feature map of the attention module is meticulously synthesized.
![]()
In the context of the attention module, x symbolizes the input feature map under consideration. The Convolution Group, denoted as Convolution1(∙), is composed of three distinct convolution layers. Convolution2(∙), designates a specialized 1 × 1 convolution layer integral to the module's architecture. The sigmoid activation function, represented by σ(∙), plays a pivotal role in the computation. Additionally, the notation ⊕ signifies channel splicing, while pool encapsulates the operational intricacies of the channel pooling procedure. The terminologies up and down delineate the operations associated with upsampling and downsampling, respectively. In the pursuit of extracting both detailed and global feature information, the network incorporates a CBlock module, as depicted in figure 1. The CBlock module, illustrated in figure 3, integrates a 3 × 3 convolution, a 5 × 5 convolution, and a 1 × 1 convolution. This strategic combination enables the module to concurrently capture diverse receptive fields of varying sizes. Through the utilization of three distinct convolutions, the CBlock module aggregates feature information across multiple receptive fields, thereby enhancing its capability to extract more efficacious feature information. To further bring down the number of parameters and, consequently, diminish computational complexity, an information distillation method is employed within the CBlock module. A dedicated distillation module is designed to supplant both the 3 × 3 convolution and 5 × 5 convolution within the CBlock module, as elucidated in figure 4. This distillation module structure, outlined in figure 4, involves channel separation, where a quarter of the feature map channels are retained, while the remaining three-quarters persist for subsequent feature extraction. Subsequently, these features are amalgamated through concatenation, and a 1 × 1 convolution is applied to fuse the features and reinstate the original number of channels. Figures 4 (a) and 4 (b) serve as replacements for the 3 × 3 convolution and 5 × 5 convolution in figure 3, respectively. Table 1 showcases that this approach can effectively halve the number of parameters in comparison to the original convolution method.
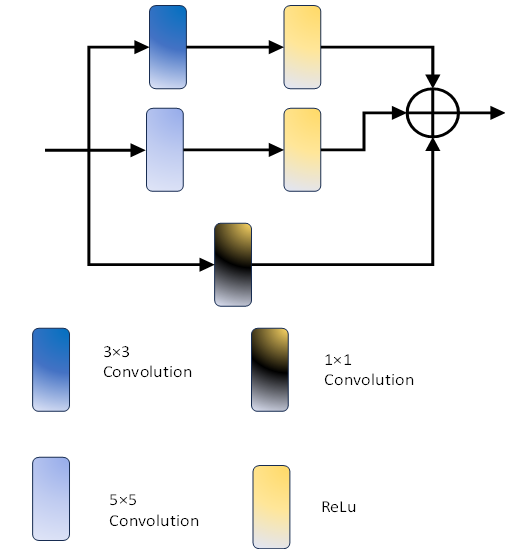
Figure 3. Module of CBlock for the proposed GAN
|
Table 1. Parameter analysis for modules of Distillation and Modules of Convolution |
||
|
|
Convolutions |
Module of distillations |
|
3×3 Convolution |
0,49 |
0,28 |
|
5×5 Convolution |
5,87 |
2,96 |
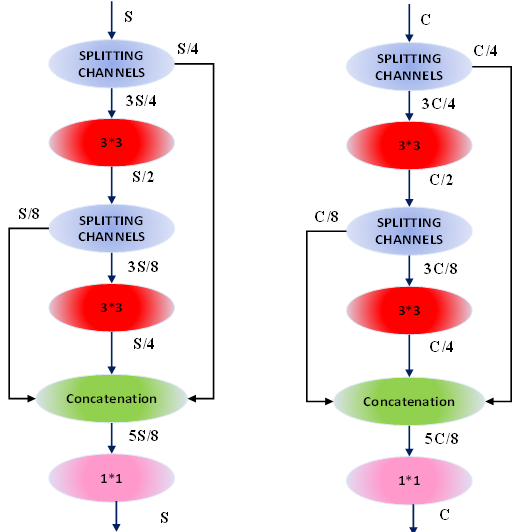
Figure 4. Flowchart for module of distillation (a) 3 × 3 module (b) 5×5 module
To seamlessly amalgamate the gleaned features, an Enhance module is meticulously designed, as depicted in figure 1. This module employs multilevel pyramid pool blocks to consolidate features obtained from distinct scales, facilitating the fusion of multiscale features and enabling the capture of more comprehensive global context information. The structural composition of the Enhance module, delineated in figure 5, involves down-sampling the feature map to three distinct scales: 1/2, 1/4, and 1/8. Subsequently, three convolution layers are applied to extract feature information, culminating in an upsampling operation to restore the size of the feature map. Concatenation operations are employed to seamlessly splice feature maps from different scales, ensuring a cohesive integration of multiscale features.
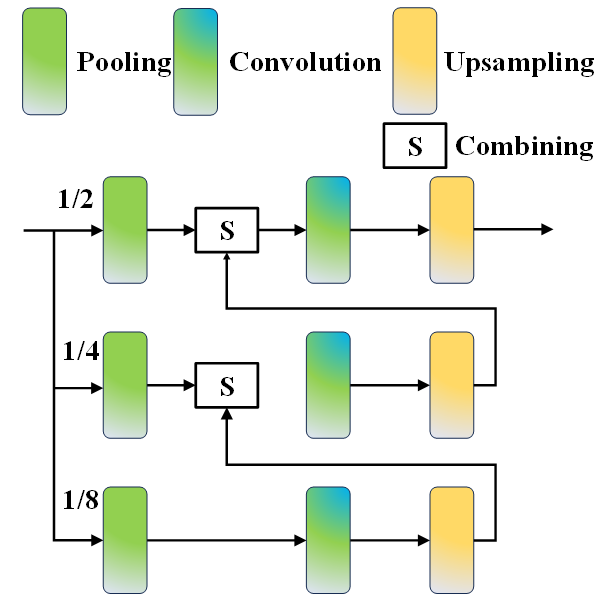
Figure 5. Enhanced module of the proposed GAN module
A multi-scale discriminative network, crafted on the foundation of the Markovian discriminative network, has been meticulously devised, as delineated in figure 6. Diverging from conventional discriminative networks, which predominantly feature full connection layers, the Markovian discriminative network exclusively incorporates convolution layers. This strategic choice is aimed at meticulously retaining intricate image details. In a bid to enhance the discrimination capabilities across multiple scales, two pooling layers are integrated into the Markovian discriminative network. The shallow features of the feature map are directly fed into the network's terminus, adeptly preventing the loss of crucial feature information and subsequently elevating dehazing performance. The discriminative network's output manifests as a single-channel matrix, subjected to averaging before being funnelled into the adversarial loss function for comprehensive network optimization.
Loss function: the loss function is built on three types of losses namely the loss (adversarial), loss (pixels) and loss (features)
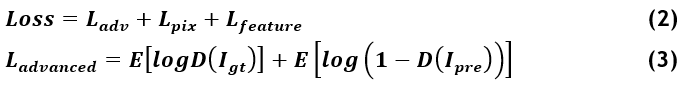
In this equation the symbol Ladvanced represent the loss (adversarial), and Lpix denotes the loss in pixel and Lfeat represents loss of features. The loss (adversarial) represents the original loss in Generative Adversarial Network designed. This is displayed in equation (3).
![]()
The result of the GAN is denoted by the symbol Ipre and the picture devoid of Hazing is denoted by the symbol Igt. The discriminator is denoted by the symbol D. The loss in pixels is utilized to reduce the space between the picture that is free of haze and the picture with haze. Lfeature gives us the extent of the loss od features in the image.
![]()
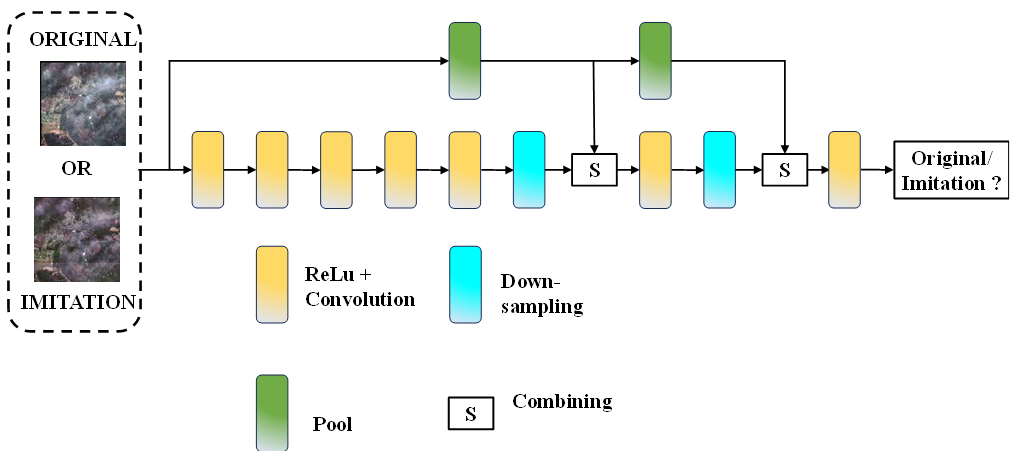
Figure 6. Developed network (discriminative)
Simulation Procedure
Within this segment, an exhaustive assessment of diverse methodologies undertaken on the RICE-I dataset. A comparative analysis unfolds, juxtaposing the proposed approach against two distinct dehazing methodologies: the DCP method,(14) the AOD-Net method.(15) To gauge the quantitative efficacy of each method, two evaluative metrics come to the fore: PSNR (Peak Signal to Noise Ratio) and the SSIM (Structural Similarity). Ultimately, an ablation study is conducted, meticulously scrutinizing and validating the efficacy of individual modules constituting the network.
Discussion on the dataset considered: the RICE-I: The RICE-I Dataset, encompassing 500 pairs of images, delineates a meticulous compilation wherein each pair exhibits images with both cloud and cloudless conditions, possessing a dimensionality of 512 × 512. The selection process entails a random extraction of 350 pairs for the training set, 50 pairs for the validation set, and 100 pairs for the test set within each dataset.
![]()
The selection process involves randomly choosing 350 images for the training set, 50 images for the validation dataset, and 100 images for the test set within each dataset. To quantitatively compare the efficacy of the proposed method against others, two evaluation indices, namely PSNR and SSIM, are utilized. In equation (6) PNSR expression is presented where the term MAX1 denotes the maximal value of coloration of the pixels of the picture considered and the Root Mean Square Error is denoted by the term RMSE.
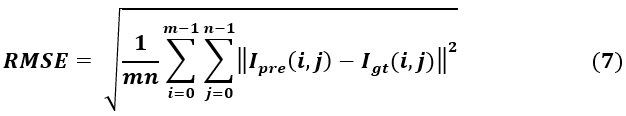
The equation (7) gives us the procedure of evaluating the RMSE for the proposed method. And the terms m and n represents the dimensions of the picture considered. The terms Ipre represents the image where the dehazing has been done and the term Igt denotes the image that is free of hazes.
![]()
The equation (8) gives the values of the SSIM calculated at each and every pixel in the picture where the average of the variable x is given by the symbol μx and the average of the variable y is given by the symbol μy. The symbols σx and σy represent the variances of the variables x and y. While the covariances are denoted by the symbols σxy.
Simulation Implementation Procedure: in the conducted experiment, the training of the network spanned 20 epochs. The optimization of the network was achieved through the Adam optimizer, and the loss function was employed to impose constraints on the network. The parameters \( \beta_1 \) and \( \beta_2 \) were specifically set to 0,9 and 0,999, respectively. The learning rate was established at 1 × 10^(-4). The chosen batch size for the training process was 2, and other parameters were initialized to zero. The experimental setup utilized the Ubuntu 18,04 operating system. The GPU employed for computations was the NVIDIA GeForce GTX 2080ti, and the deep learning framework employed throughout the experiment was PyTorch.
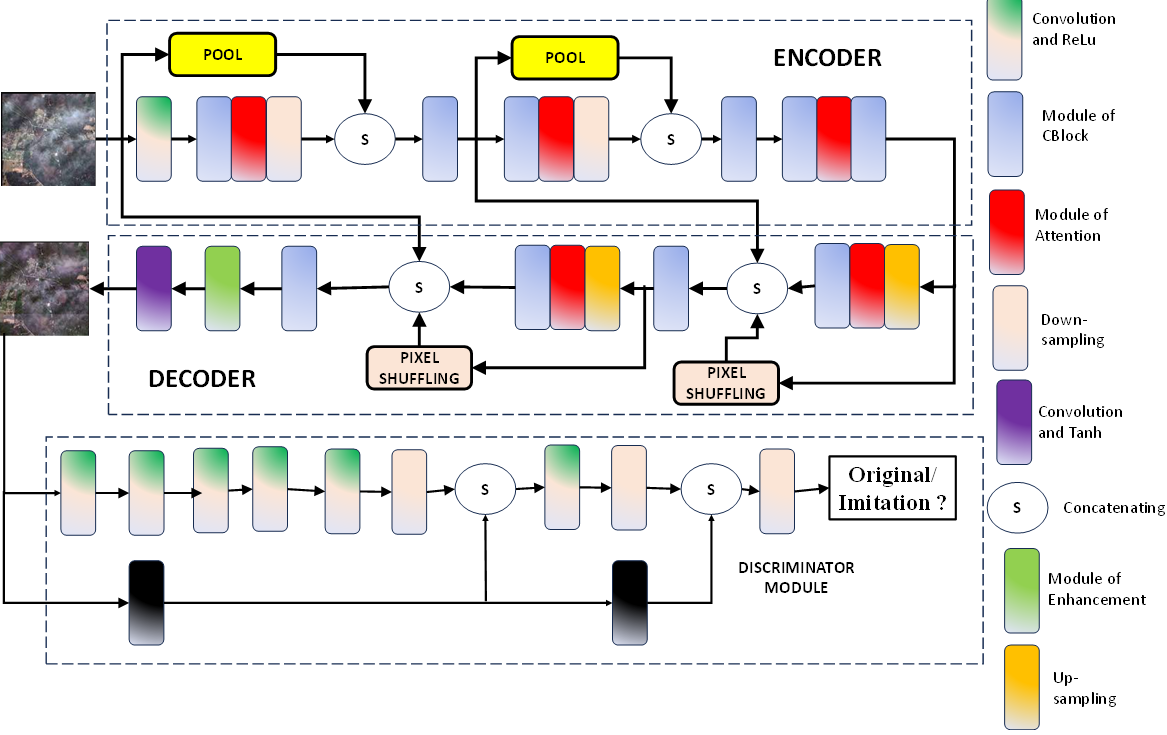
Figure 7. Integrated diagram of the dehazing framework along with the Generator and Discriminator module
|
Table 2. Analysis of results of Dehazing algorithms on the RICE-I Data Set |
|||
|
|
DCP(14) |
AOD-Net(15) |
Proposed Solution |
|
PSNR |
14,3817 |
20,1562 |
31,2311 |
|
SSIM |
0,5231 |
0,8142 |
0,9144 |
Simulating on the Dataset of RICE-I
Five images were selected at random from the RICE-I test set to serve as input for comparison with two alternative methods: the DCP method and the AOD-Net method. The results, depicted in figure 7, showcase hazy images, dehazing outcomes, and haze-free references. In the initial row, despite the DCP method effectively eliminating haze, it introduces color darkening, negatively impacting the visual presentation. The dehazed image produced by the AOD-Net method remains significantly hazy. In contrast, the proposed method's dehazed image is notably clearer and more closely resembles the haze-free reference. Moving to the sixth and seventh rows, the dehazed results from the DCP method display conspicuous color deviations. Moreover, the AOD-Net method prove ineffective in entirely eliminating the atmospheric haze.
RESULTS AND DISCUSSION
According to the analysis, the DCP method yields dehazed images characterized by the most severe color distortion. For a quantitative evaluation of the efficacy of various dehazing methods, three performance metrics, namely PSNR and SSIM are employed to compare the DCP method, AOD-Net method and the proposed method using the RICE-I dataset's test set. The test dataset comprises 100 image pairs that are randomly selected from the RICE-I dataset, with a specific focus on images featuring clouds. These images serve as a robust evaluation platform for assessing the dehazing capabilities of the different methods. Both the corresponding haze-free images and the dehazed images from the test set are utilized to compute PSNR and SSIM. The tabulated results in table 2 reveal the quantitative performance metrics. The PSNR values for the DCP method, AOD-Net method and the proposed method are 14,3817, 20,1562 and 31,2311 respectively. Similarly, the SSIM values for the DCP method, AOD-Net method and the proposed method are 0,5231, 0,8142 and 0,9144 respectively. Notably, the proposed method attains the highest values in both PSNR and SSIM, indicating superior dehazing performance compared with the other methods.

Figure 8. Comparison of proposed method(iv) with DCP(14) (ii), AOD-Net(15) (iii) and original hazy image (i)
|
Table 3. Comparing of the time to dehaze on the concerned Dataset |
|||
|
|
DCP(14) |
AOD-Net(15) |
Proposed Solution |
|
Train (hours) |
0,68 |
4,03 |
6,79 |
|
Testing (seconds) |
0,023 |
0,0723 |
0,0912 |
|
Parameters (MegaBytes) |
0,01 |
2,73 |
24 |
CONCLUSIONS
Within this manuscript, a novel encoder-decoder network, hinging on the principles of a generative adversarial network, is introduced for the explicit purpose of image dehazing. The generative network, a pivotal component, comprises both an encoding network and a decoding network, each tailored to intricate specifications. Fundamental to its architecture are newly devised modules, including an attention module, distillation module, CBlock module, enhance module, along with short and local skip connections, collectively engineered to bolster the network's capacity to extract pertinent local and global feature information effectively.
REFERENCES
1. Liu J, Wang S, Wang X, Ju M, Zhang D. A review of remote sensing image dehazing. Sensors. 2021;21(11):3926.
2. Hu A, Xie Z, Xu Y, Xie M, Wu L, Qiu Q. Unsupervised haze removal for high-resolution optical remote-sensing images based on improved generative adversarial networks. Remote Sensing. 2020;12(24):4162
3. Gu Z, Zhan Z, Yuan Q, Yan L. Single remote sensing image dehazing using a prior-based dense attentive network. Remote Sensing. 2019;11(24):3008.
4. Huang B, Zhi L, Yang C, Sun F, Song Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2020:1806-1813.
5. Jiang B, Chen G, Wang J, Ma H, Wang L, Wang Y, Chen X. Deep dehazing network for remote sensing image with non-uniform haze. Remote Sensing. 2021;13(21):4443.
6. Gui J, Cong X, Cao Y, Ren W, Zhang J, Zhang J, Cao J, Tao D. A comprehensive survey and taxonomy on single image dehazing based on deep learning. ACM Computing Surveys. 2023;55(13s):1-37.
7. Ni W, Gao X, Wang Y. Single satellite image dehazing via linear intensity transformation and local property analysis. Neurocomputing. 2016;175:25-39.
8. Zhang S, Zhang X, Wan S, Ren W, Zhao L, Shen L. Generative adversarial and self-supervised dehazing network. IEEE Trans Ind Inform. 2023 Oct 12:1-11. doi: 10.1109/TII.2023.3316180.
9. Jin Y, Chen J, Tian F, Hu K. LFD-Net: Lightweight Feature-Interaction Dehazing Network for Real-Time Remote Sensing Tasks. IEEE J Sel Top Appl Earth Obs Remote Sens. 2023 Sep 6;6:9139-9153. doi: 10.1109/JSTARS.2023.3312515.
10. Zhang S, Zhang X, Shen L. Dual Multi-scale Dehazing Network. IEEE Access. 2023 Jul 18:84699-84708. doi: 10.1109/ACCESS.2023.3296592.
11. He K, Sun J, Tang X. Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell. 2011 Dec;33(12):2341-2353. doi: 10.1109/TPAMI.2010.168.
12. Zhu Q, Mai J, Shao L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans Image Process. 2015 Nov;24(11):3522-3533. doi: 10.1109/TIP.2015.2446191.
13. Akshay D, Patil PW, Murala S. An end-to-end network for image de-hazing and beyond. IEEE Trans Emerg Top Comput Intell. 2020;6(1):159-170.
14. Li Y, Chen X. A coarse-to-fine two-stage attentive network for haze removal of remote sensing images. IEEE Geosci Remote Sens Lett. 2020;18(10):1751-1755.
15. Chen X, Li Y, Dai L, Kong C. Hybrid high-resolution learning for single remote sensing satellite image Dehazing. IEEE Geosci Remote Sens Lett. 2021;19:1-5. doi: 10.1109/LGRS.2021.3072917.
16. Li Y, Liu Y, Yan Q, Zhang K. Deep dehazing network with latent ensembling architecture and adversarial learning. IEEE Trans Image Process. 2020;30:1354-1368.
FINANCING
The authors did not receive financing for the development of this research.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: Sudhamalla Mallesh.
Data curation: Sudhamalla Mallesh.
Formal analysis: Sudhamalla Mallesh.
Acquisition of funds: Sudhamalla Mallesh.
Research: Sudhamalla Mallesh.
Methodology: Sudhamalla Mallesh.
Project management: Sudhamalla Mallesh, D. Haripriya.
Resources: Sudhamalla Mallesh, D. Haripriya.
Software: Sudhamalla Mallesh, D. Haripriya.
Supervision: Sudhamalla Mallesh, D. Haripriya.
Validation: Sudhamalla Mallesh, D. Haripriya.
Display: Sudhamalla Mallesh, D. Haripriya.
Drafting - original draft: Sudhamalla Mallesh, D. Haripriya.
Writing - proofreading and editing: Sudhamalla Mallesh, D. Haripriya.